https://docs.sweeting.me/s/archivebox-plugin-ecosystem-announcement
28531 views
 # Big
changes are coming to ArchiveBox! *New features coming to the future
of self-hosting internet archives: a full plugin ecosystem, P2P
sharing between instances, Cloudflare/CAPTCHA solving, auto-logins,
and more...*.
# Big
changes are coming to ArchiveBox! *New features coming to the future
of self-hosting internet archives: a full plugin ecosystem, P2P
sharing between instances, Cloudflare/CAPTCHA solving, auto-logins,
and more...*.
In the wake of the [recent attack]
(https://www.theverge.com/2024/10/9/24266419/
internet-archive-ddos-attack-pop-up-message) against Archive.org,
[ArchiveBox](https://archivebox.io) has been getting some increased
attention from people wondering how to **self-host their own internet
archives**.  ArchiveBox is a strong
supporter of Archive.org and their mission to preserve all of human
knowledge. We've been donating for years, and we urge you to do the
same, they provide an invaluable service for all of humanity. We
completely condemn the DDoS and defacement of their site, and hope it
never happens again. Realistically though, they are an attractive
target for people who want to supress information or [start IP
lawsuits](https://blog.archive.org/2024/07/01/
what-happened-last-friday-in-hachette-v-internet-archive/), and this
may not be the last time this happens...

> We envision a future where the world has both a robust
centralized archive through Archive.org, and a widespread network of
decentralized ArchiveBox.io instances. 

### The Limits of
Public Archives In an era where fear of public scrutiny is very
tangible, people are afraid of archiving things for eternity. As a
result, people choose not to archive at all, effectively erasing that
history forever. We think people should have the power to archive
what *matters to them*, on an individual basis. We also think people
should be able to *share* these archives with only the people they
want. The modern web is a different beast than it was in the 90's and
people don't necessarily want everything to be public anymore.
Internet archiving tooling should keep up with the times and provide
solutions to archive private and semi-private content in this
changing landscape. --- #### Who cares about saving stuff? All of us
have content that we care about, that we want to see preserved, but
privately: - families might want to preserve their photo albums off
Facebook, Flickr, Instagram - individuals might want to save their
bookmarks, social feeds, or chats from Signal/Discord - companies
might want to save their internal documents, old sites, competitor
analyses, etc. *Archiving private content like this [has some
inherent security challenges](https://news.ycombinator.com/item?id=
41861455), and should be done with care.
(e.g. how do you prevent
the cookies used to access the content from being leaked in the
archive snapshots?)* --- #### What if the content is evil?
There is also content that unfairly benefits from the existence of
free public archives like Archive.org, because they act as a mirror/
amplifier when original sites get taken down. There is value in
preserving racism, violence, and hate speech for litigation and
historical record, but is there a way we can do it without
effectively providing free *public* hosting for it? 
---
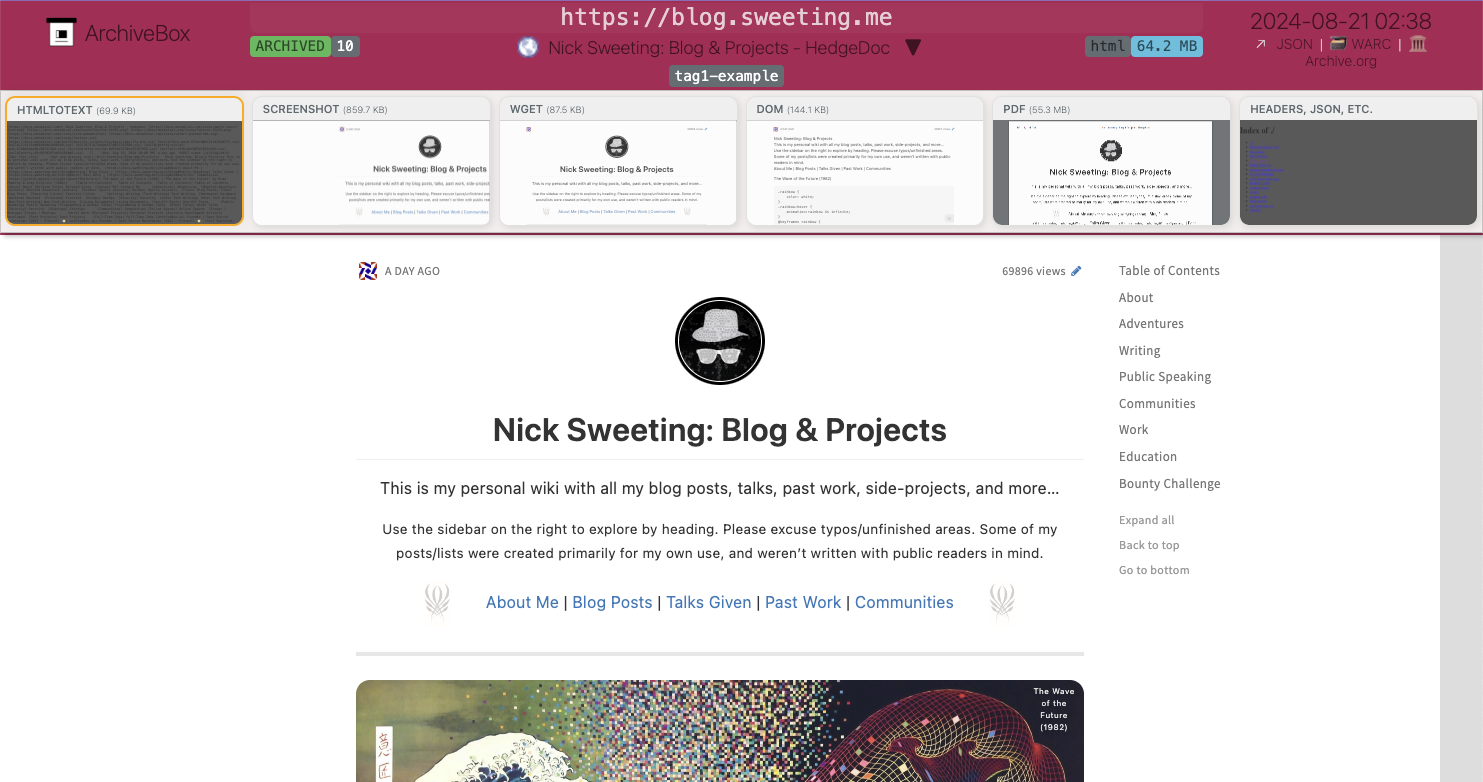
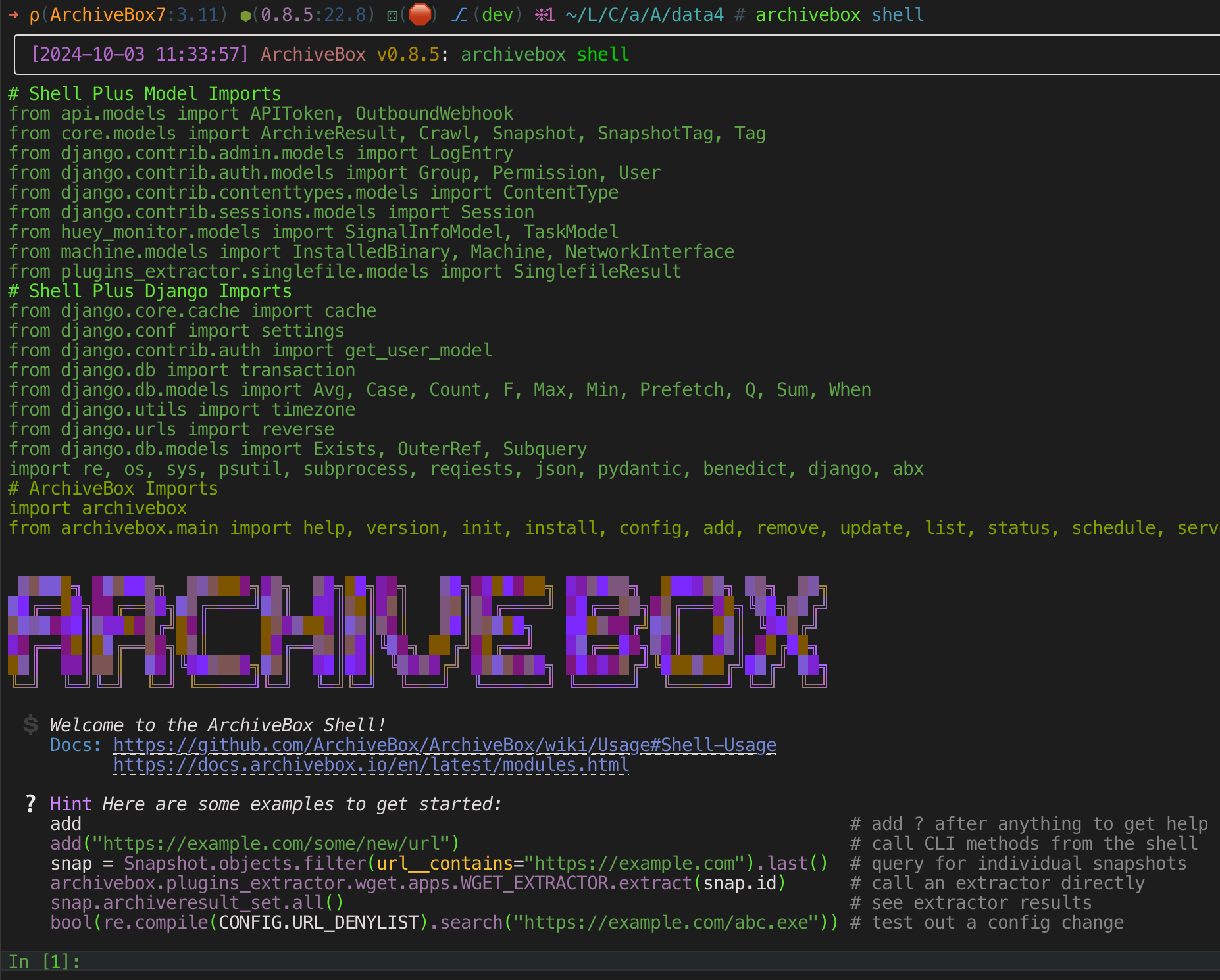
## Introducing ArchiveBox's New Plugin Ecosystem
[ArchiveBox v0.8](https://github.com/ArchiveBox/
ArchiveBox/releases) is shaping up to be the [**biggest release in
the project's history**](https://github.com/ArchiveBox/ArchiveBox/
pull/1311). We've completely re-architected the internals for speed
and performance, and we've opened up access to allow for a new plugin
ecosystem to provide community-supported features. 
We want to follow in the footsteps of great projects like [NextCloud]
(https://apps.nextcloud.com/) and [Home Assistant](https://
www.home-assistant.io/addons/), and provide a robust "app store" for
functionality around bookmark management, web scraping, capture, and
sharing. #### Here's just a taste of some of the first plugins that
will be provided: - `yt-dlp` for video, audio, subtitles, from
Youtube, Soundcloud, YouKu, and more... - `papers-dl` for automatic
download of scientific paper PDFs when DOI numbers are seen -
`gallery-dl` to download photo galleries from Flickr, Instagram, and
more - `forum-dl` for download of older forums and deeply nested
comment threads - `readability` for article text extraction to .txt,
.md, .epub - **`ai`** to send page screenshot + text w/ a custom
prompt to an LLM + save the response - **`webhooks`** trigger any
external API, ping Slack, N8N, etc. whenever some results are saved -
and [many more...](https://github.com/ArchiveBox/ArchiveBox/tree/dev/
archivebox/plugins_extractor) If you're curious, the plugin system is
based on the excellent, well-established libraries [pluggy](https://
pluggy.readthedocs.io/en/stable/index.html) and [pydantic](https://
pydantic-docs.helpmanual.io/). It was a fun challenge to develop a
plugin system without over-engineering it, and it took a few
iterations to get right! > I'm excited for the future this will
bring! It will allow us to keep the **core** lean and high-quality
while getting community help supporting a **wide periphery** of
plugins.
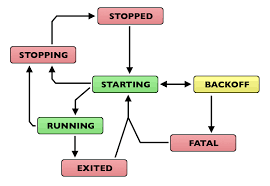
#### Other things in the works: - There is an
all-new [`REST API`](https://demo.archivebox.io/api) built with
`django-ninja`, already [available in BETA](https://github.com/
ArchiveBox/ArchiveBox/releases) - [Support for external storage]
(https://github.com/ArchiveBox/ArchiveBox/wiki/Setting-Up-Storage)
(AWS/B2/GCP/Google Drive/etc.) (via `rclone`) was added - We've
started adding the beginnings of a content-addressable store system
with unique "ABID"s (identifiers based on URL + timestamp) that can
be shared between instances. This will help us build BitTorrent/
IPFS-backed P2P sharing between instances in the future. - We've
added a background job system using [`huey`](https://
huey.readthedocs.io/) - new auto-install system `archivebox install`
(no more complex `apt` dependencies) *(plugin's cross-platform
runtime dependencies are very hard to package and maintain, check out
our new [`pydantic-pkgr`](https://github.com/ArchiveBox/
pydantic-pkgr) library that solves this and use it in your projects!)
* > ArchiveBox is designed to be local-first with [**SQLite**](https:
//www.sqlite.org/famous.html), P2P will always be optional.
###
# For the minimalists who just want something simple: If you're an
existing ArchiveBox user and feel like this is more than you need,
don't worry, we're also releasing a new tool called `abx-dl` that
will work like like `yt-dlp` or `gallery-dl`. It will provide a
one-shot CLI to quickly download *all* the content on any URL you
provide it without having to worry about complex configuration,
plugins, setting up a collection, etc.
---
### Try out
the new BETA now! ```bash pip install archivebox==0.8.5rc44
archivebox install # or docker pull archivebox/archivebox:dev ```
*Read the release notes for the new BETAs on our [Releases](https://
github.com/ArchiveBox/ArchiveBox/releases) page on Github.* *[Join
the discussion on HN](https://news.ycombinator.com/item?id=41860909)
or over on our [Zulip forum](https://zulip.archivebox.io/).* [?] *Or
[hire us](https://github.com/ArchiveBox/archivebox#
-professional-integration) to provide digital preservation for your
org (we provide CAPTCHA/Cloudflare bypass, popup/ad hiding, on-prem/
cloud, SAML/SSO integration, audit logging, and more).*


 [Donate to ArchiveBox](https://hcb.hackclub.com/donations/
start/archivebox) (tax-deductible!) to support our
open-source development.
[Donate to ArchiveBox](https://hcb.hackclub.com/donations/
start/archivebox) (tax-deductible!) to support our
open-source development.
Remember to also donate to
[Archive.org](https://help.archive.org/help/
how-do-i-donate-to-the-internet-archive/) (not affiliated)
to help them with the attack!